
はじめに
最近、ベイズ最適化による実験の短縮が流行っているようで。ベイズ最適化について調べてみると、関数の最適化であったり、機械学習におけるハイパーパラメータの調整に使われるケースが多いイメージがあります。
本記事では「ベイズ最適化を実験に使う」ことに重点を置いて話します。
実験におけるベイズ最適化の利用
ベイズ最適化を実験で使用する場合、図1に示すフローが一般的です。

ベイズ最適化では、「ガウス過程回帰」という回帰の親玉のような手法を用いて、実験データをモデル化(入力データに対して予測値を返す関数を作る)します。ガウス過程回帰では、線形回帰では表現できないような複雑な応答を表現することが出来ます。
ガウス過程回帰ではある実験条件における予測値µと、データの予測分散σ(不確かさ)を計算することができ、このµとσを考慮した「獲得関数」という評価値に基づいて、最適値の提案を行います。具体例を次の章で説明します。

Pythonによる実践書としては、こちらもおすすめです。

デモ
よくあるベイズ最適化のデモは、図3のような1変数のものです。

図2①はある実験点と真の関数(未知)を示しています。同図②では実験データに基づいてガウス過程回帰モデルを作成しています(黄線)。灰色の帯は予測分散σを表しており、この灰色の大きさσと黄色の線による予測値µを
獲得関数 = µ+3σ
で計算したものが獲得関数です(赤線)。この獲得関数の最大点が次の実験点です。
上で定義した獲得関数はUCBというもので、ほかにもEI、PIなどが存在します。3σの係数"3"の部分を変化させることで、予測値µを優先する「活用」と、分散σを優先する「探索」のどちらに重点を置くかを調整することができます。
図2②では獲得関数が威力を発揮しています。実験されていない右側の領域ではモデル(黄線)の予測値があまり大きくありませんが、灰色の帯(分からなさ)が大きいために獲得関数が大きくなり、実際の最大点に近い条件が提案されていますね。
このように、ベイズ最適化では局所的な最適値にとどまらず、未知の点を「探索」する仕組みがあるので、自動的な実験条件の最適化ができます。
ただ、これだとイマイチありがたみが無い気がするんですね。というのも、1変数なら最初から数点実験して傾向取ればいいじゃん!ってなります。
そこで、本記事では2変数のベイズ最適化のデモもやってみました。下図において、要因数AおよびBが説明変数で、特性yが目的変数です。
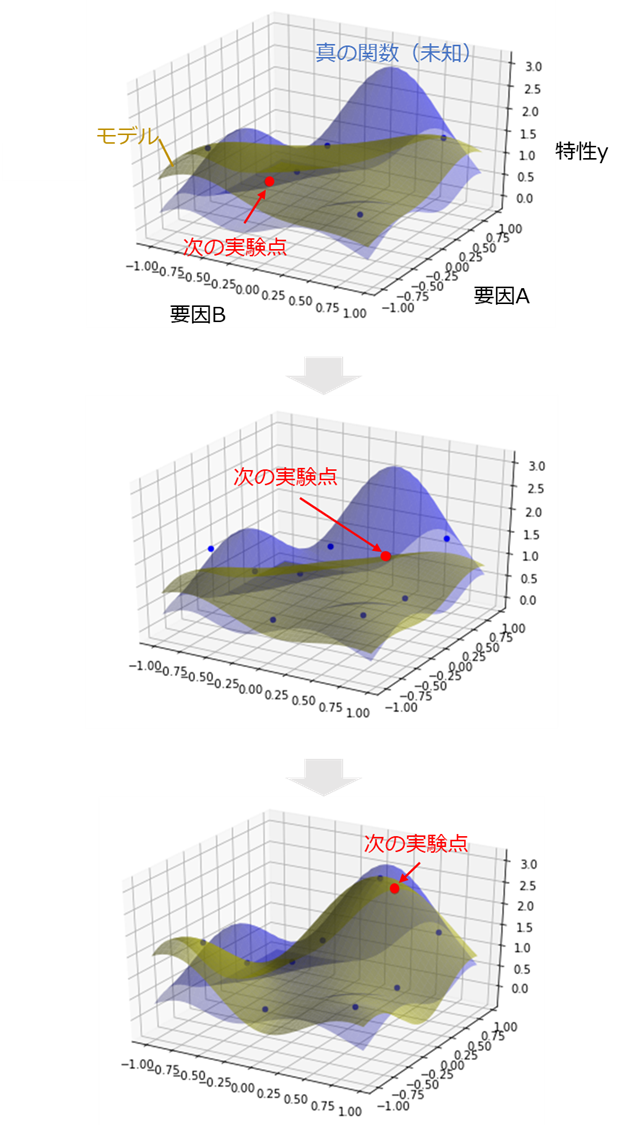
こっちの方が実験っぽいかなと思います。図3のすべてのグラフにおいて、青色の曲面が真の関数で(実際は分からない)、黄色の曲面がガウス過程回帰モデルです。
実験が進むにつれてモデルが変化していき、真の関数の最大点に近い条件が提案されていることが見て取れます。
実装
図3のデモをするためのPythonコードをこちらに書きました。ガウス過程回帰はSckiit-learnのページを参考にしました。
import numpy as np
from matplotlib import pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, WhiteKernel, DotProduct, ConstantKernel
from mpl_toolkits.mplot3d import Axes3D
#獲得関数
def aq(mu, sigma, N):
a = mu+3*sigma # a = mu + k * sigmaでkを実験回数で変更してもよい
i = np.argmax(a)
return a, i
#真の関数(実際は分からない)
def g(X,Y):
u = 2*np.exp(-7*((X+0.5)**2+(Y+0.5)**2-(X+0.5)*(Y+0.5)))
v = 3*np.exp(-5*((X-0.3)**2+(Y-0.5)**2-(X-0.3)*(Y-0.5)))
w = np.exp(-3*((X-0.6)**2+(Y+0.6)**2-(X-0.6)*(Y+0.6)))
return u+v+w
#初期の実験点
D_measured = np.array([[-0.7, -0.7],
[-0.7, 0.7],
[0.7, -0.7],
[0.7, 0.7],
[0,0]])
NP = np.array(0,0)
NP = np.delete(NP, 0, 0)
print("Reset NP:", NP)
print(D_measured)
print(NP.shape[0], "Newly measured points: ")
if NP.shape[0] > 0:
print("The latest data measured at x=", NP[-1])
"""以下コードの繰返し"""
# 観測
D_train = np.vstack((D_measured, NP))
np.random.seed(3)
Z_train = np.zeros(len(D_train))
for i in range(0,len(D_train)):
Z_train[i] = g(D_train[i][0], D_train[i][1])+np.random.standard_normal(1)*0.1
# ガウス過程回帰モデルの構築
kernel = ConstantKernel()*RBF(length_scale_bounds=[0.01, 0.5])+WhiteKernel(noise_level_bounds=[1e-5, 0.5])
GP = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=20)
GP.fit(D_train, Z_train)
print("Kernel: ", GP.kernel_)
# ガウス過程回帰モデルによる予測値の計算
X1 = np.arange(-1, 1, 0.05)
X2 = np.arange(-1, 1, 0.05)
# Meshgrid for 3D plot
X1X1, X2X2 = np.meshgrid(X1, X2, indexing='ij')
#X1X2 is argument for GP
X1X2 = np.c_[X1X1.flatten(), X2X2.flatten()]
G, SD = GP.predict(X1X2, return_std=True)
G_mesh = G.reshape((len(X1), len(X2)))#mesh for 3D plot
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(X1X1, X2X2, G_mesh, rstride=1, cstride=1, alpha=0.5, color='y')#prediction
for i in range(0, len(D_train)):
ax.scatter(D_train[i][0], D_train[i][1], Z_train[i], color='b')
# 真の関数(実際は分からない)の表示
Z_true = np.zeros(len(X1X2))
for i in range(0,len(X1X2)):
Z_true[i] = g(X1X2[i][0], X1X2[i][1])
Z_true_mesh = Z_true.reshape((len(X1), len(X2)))
ax.plot_surface(X1X1, X2X2, Z_true_mesh, rstride=1, cstride=1, alpha=0.3, color='b')#true function
# 次の実験点の提案
# 獲得関数の計算
A, index = aq(G, SD, len(X1X2))
A_mesh = A.reshape((len(X1), len(X2)))
indices = np.argwhere(A_mesh==A[index])#the location of maximum Aq
NP_x1 = X1[indices[0][0]]
NP_x2 = X2[indices[0][1]]
ax.scatter(NP_x1, NP_x2, G[index], color='r', s=50)
plt.show()
※ ”””以下コードの繰返し"""~”””以上コードの繰返し"""部分を実行するたびに新しい実験点が提案されます。ダサくてすみません(笑)
ベイズ最適化による実験の短縮についての疑問
前述の図3に示したように、ガウス過程回帰は非常に柔軟で、複雑な応答を滑らかな曲線で表現することが出来ます。ベイズ最適化では、そのガウス過程回帰モデルを利用して、効率的な実験点を自動的に提案してくれます。
そのため、「実験の自動化」という点では間違いなく利用価値があります。しかし、ベイズ最適化それ自身には実験を短縮する効果はないのでは?と個人的には思います。
実際にガウス過程をやってみればわかるのですが、ガウス過程回帰は「観測した点の滑らかに近似するだけ」の手法です。別の言い方をすれば、
観測していない点に関しては何もわからない。
事実、未知の領域について何も分からないから、獲得関数に予測分散を反映して実験していない点を提案するようにしているわけです(図4)。

これは人間と同じどころか、人間のように現象の物理を考えたりしているわけではないので、行き当たりばったりのモグラたたき探索になる危険性があります。
ベイズ最適化によって実験回数が大幅に短縮する場合、それは線形モデルのような簡単なモデルでも表せる現象である可能性が高いです。この場合、数式としての解釈ができる線形モデルの方が適していると思います。
複雑なモデルでしか表せない現象であれば、先ほど言ったように、ベイズ最適化は自動的な実験条件の探索として利用する価値があります。しかし複雑な現象では「実験しなければわからない」ため、実験回数の短縮はできないでしょう。
本当の意味で、実験回数を削減するためには、実験していない点の予測(外挿)ができる必要があります。外挿は、様々な物理を考慮して総合的に判断できる「人間」にしか今のところできないんじゃないかな?と思います。それが出来るスーパー人工知能が現れたら恐ろしいですが...
ベイズ最適化と要因の数と実験計画法の利用
多くの変数(要因)を調整して、最適な実験条件を見つけたいとき、すべての変数を用いてベイズ最適化を行うことは効率的とは言えません。なぜなら、変数が増えれば増えるほど、実験していない領域が多く(変数空間の外側の領域は変数の数のべき乗で増える)、探索を重視する傾向のあるベイズ最適化の初期段階では、実験領域の端ばかり提案するからです。数個の要因を扱う場合は、それでもいいのですが、要因が10, 20となると、実験がいつまでたっても終わりません。
そのため、多くの要因を用いた最適化を行う場合、スクリーニングの目的で実験計画法を用いて、効果の小さい要因を除外し、効果の大きな要因だけでベイズ最適化を行うべきです。
他の分野についてはよく分かりませんが、少なくとも工学の分野に関して言えば、オッカムの剃刀(ある事柄を説明するためには、必要以上に多くを仮定するべきでない)が正しいと思います。
まとめると、
- 実験計画法により多くの要因(例えば10~20個)から効果の大きな要因(例えば3~6個)に絞る。
- ベイズ最適化の利用
このような、実験計画法+ベイズ最適化という2ステップであれば、多くの要因を扱う実験の回数削減につながるでしょう。スクリーニング目的の実験計画としては、Plackett-Burmman計画や決定的スクリーニング計画をお勧めします。
実験計画法の参考書としては、こちらでお勧めしています。